GET 방식
웹 개발 처음 시작하면 이런 거 한 번쯤 궁금하실 거예요. 로그인 폼은 왜 뭔가 “숨겨서” 보내는 느낌이고, 검색은 왜 주소창에 내가 친 단어가 그대로 보이냐고요. 저도 그때는 그냥 “원래 웹은 이런가 보다” 하고 넘겼는데, 조금만 파고 들어가 보니까 답은 딱 하나더라고요. HTTP 메서드 차이였습니다.
우리가 웹페이지 열고, 친구가 던져준 상품 링크 눌러보고, 맛집 검색하는 그 평범한 순간들 있죠. 그 뒤에서 제일 자주 일하는 녀석이 GET입니다. 오늘은 GET이 정확히 뭐고, 왜 “조회는 GET”이라고들 하는지, 그리고 어디서 삽질이 터지는지까지 편하게 풀어볼게요.
GET 방식의 기본 개념과 특징

GET 방식이란?
브라우저(클라이언트)가 서버한테 “저기 있는 자료 좀 가져다줘요”라고 요청할 때 쓰는 가장 기본적인 약속이 GET입니다. 도서관으로 비유하면, 사서한테 “이 책 어디 있어요?” 하고 물어보는 느낌이에요. 책 내용을 바꾸는 게 아니라, 위치나 정보를 조회하는 거죠.
우리가 주소창에 URL 치고 엔터 누르는 그 순간, 브라우저는 서버로 “이 주소에 있는 거 주세요(GET)”라고 요청을 날립니다. 서버는 그 요청을 보고 웹페이지든 이미지든 필요한 걸 찾아서 브라우저로 보내주고, 우리는 화면에서 결과를 보게 되는 거고요.
GET의 핵심 성격은 두 가지로 많이 정리합니다. 서버 데이터를 건드리지 않는 안전성(Safety)과, 같은 요청을 여러 번 해도 결과가 같다는 멱등성(Idempotency)이요.
안전성은 말 그대로 GET이 서버 데이터를 변경하거나 삭제하지 않는다는 뜻입니다. “보기만 한다”에 가까워요. 멱등성은 같은 요청을 한 번 하든 백 번 하든 서버 입장에서 결과가 같다는 의미고요. 제가 좋아하는 뮤직비디오를 100번 본다고 영상 파일이 바뀌진 않잖아요. 그 느낌입니다.
| 특징 | 설명 |
|---|---|
| 안전성 (Safety) | 서버 데이터 변경/삭제 없이 오직 읽기만 함 |
| 멱등성 (Idempotency) | 같은 요청을 여러 번 보내도 결과가 항상 같음 |
GET 요청은 보통 GET /경로?이름=값 HTTP/1.1처럼 생겼습니다. 여기서 물음표(?) 뒤에 붙는 이름=값이 바로 쿼리 스트링(Query String)이고요. 서버한테 “이 조건으로 찾아줘요”라고 던지는 질문지 같은 역할을 합니다. 검색어 전달하거나, 쇼핑몰에서 정렬 기준 넘길 때 딱 이거 쓰죠.
> 웹 구조 쪽에서 유명한 로이 필딩(Roy Fielding)도 GET을 “웹의 기본 정보 검색 메커니즘”이라고 얘기하면서 중요하다고 강조한 적이 있습니다.

GET 방식은 어떤 특징을 가질까요?
GET은 목적이 “조회”인 만큼 성격이 꽤 뚜렷합니다. 그중에서 초보 때 제일 체감되는 건 URL에 정보가 다 보이는 가시성과, URL 길이 제한이에요.
가시성 (Visibility)
정보가 URL에 직접 노출돼서 공유나 즐겨찾기가 편합니다.
다만 민감한 정보가 URL에 섞이면 보안 사고로 바로 이어질 수 있어요.
URL 길이 제한
브라우저나 서버 쪽에서 너무 긴 URL을 자체적으로 막는 경우가 많아서 대용량 데이터 전송은 어렵습니다.
그래서 “간단한 조회” 쪽으로 용도가 자연스럽게 고정되는 편이에요.
가시성은 말 그대로 GET 요청 정보가 주소창에 훤히 보인다는 뜻입니다. 검색어, 페이지 번호 같은 게 URL에 그대로 찍히죠. 이게 장점이기도 한 게, 링크 복사해서 공유하면 상대도 똑같은 화면을 바로 볼 수 있거든요. 즐겨찾기도 편하고요.
근데 반대로, 비밀번호나 주민등록번호 같은 민감한 값이 URL에 들어가면 진짜 위험합니다. 브라우저 방문 기록에도 남고, 서버 로그에도 남고, 상황에 따라서는 다른 곳으로 새어 나갈 수도 있어요.
실무 썰 하나만 얹어볼게요. 예전에 맛집 추천 서비스 백엔드 API 만들 때, 처음엔 필터 조건을 전부 POST로 받으려고 했던 적이 있습니다. “조건 많으니까 POST가 안전하겠지” 이런 단순한 생각이었죠. 근데 팀장님이 딱 한마디 하시더라고요. “이건 조회잖아. GET으로 가야지.”
그래서 위도/경도, 카테고리, 정렬 같은 걸 쿼리 스트링으로 바꿔서 붙였는데, URL만 봐도 요청 의도가 딱 보이고 캐싱이나 디버깅도 훨씬 편해졌습니다. 그때 느꼈어요. 도구는 “편해 보이는 거”가 아니라 “맞는 자리에 쓰는 거”가 더 중요하구나 하고요.
URL 길이 제한은 좀 애매한 포인트인데요. HTTP 표준 자체가 “몇 글자까지”를 딱 잘라 말하진 않습니다. 대신 브라우저나 웹 서버가 현실적으로 너무 긴 URL을 처리 못 하게 제한을 걸어두는 경우가 많아요. 그래서 사진 파일처럼 큰 데이터를 GET으로 보내는 건 사실상 어렵습니다. 답답하긴 한데, 한편으론 GET을 조회용으로만 쓰게 만드는 안전장치처럼 느껴지기도 합니다.

GET 방식의 장점, 단점 및 보안 문제

GET 방식의 장점과 단점은 무엇인가요?
기술은 다 그렇듯 GET도 장단점이 확실합니다. 언제 GET을 쓰고, 언제 다른 메서드로 가야 하는지 감이 잡히면 그때부터 “그냥 되는 코드”에서 “의도 있는 코드”로 넘어가더라고요.
GET의 제일 큰 장점은 단순하고 빠르다는 점입니다. 한 번 요청했던 결과가 브라우저나 중간 캐시 서버에 저장될 수 있어서, 같은 요청을 다시 하면 서버까지 안 가고도 빨리 뜨는 경우가 많습니다. 뉴스 사이트 두 번째부터 빨리 뜨는 거, 이런 데서 체감하실 거예요.
그리고 URL에 정보가 다 들어 있으니까 링크 공유가 정말 편합니다. 특정 조건으로 필터링된 쇼핑몰 목록 페이지를 그대로 친구한테 보내줄 수 있는 것도 이 덕분이고요.
| 장점 (Pros) | 단점 (Cons) |
|---|---|
| 단순하고 빠름 (캐싱 용이) | 보안에 취약 (URL에 민감 정보 노출) |
| URL 공유 및 즐겨찾기 편리 | URL 길이 제한 (대용량 데이터 전송 불가) |
| 서버 데이터 변경 없음 (안전성, 멱등성) | 서버 상태를 변경하는 작업에 부적합 |
단점은 딱 하나로 요약하면 “주소창에 다 보인다”입니다. 아이디, 비밀번호 같은 민감 정보가 URL에 들어가면 그대로 노출돼요. 내 PC 방문 기록에도 남고, 서버 접속 로그에도 남습니다.
> 보안 쪽에서는 “민감한 데이터는 GET으로 보내지 마라”는 얘기가 거의 상식처럼 굳어져 있습니다.
그리고 URL 길이 제한 때문에 회원가입 폼처럼 입력이 많거나, 파일 업로드 같은 건 GET으로 처리하기가 어렵습니다. 쌩초보 때 흔한 삽질이 “삭제/수정 같은 중요한 기능을 GET으로 만들어버리는 것”인데요, 이건 진짜 피하셔야 합니다. GET은 읽기 전용으로 두는 게 안전합니다.
GET 방식 보안 문제
GET의 투명함이 편하긴 한데, 그 투명함 때문에 보안 이슈가 같이 따라옵니다. 개발자라면 여기만큼은 좀 예민하게 보셔야 해요.
URL을 통한 민감 정보 노출
브라우저 방문 기록에 저장될 수 있습니다.
웹 서버 로그에도 기록됩니다.
HTTPS가 아니면 네트워크 중간에서 훔쳐볼 가능성도 커집니다.
리퍼러(Referer) 헤더를 통한 정보 유출
이전 페이지 URL에 민감 정보가 있으면, 다른 사이트로 넘어갈 때 같이 전달될 수 있습니다.
크로스 사이트 요청 위조(CSRF) 취약
사용자 모르게 공격자가 만든 요청이 전송될 수 있습니다.
가장 직접적인 건 URL 민감 정보 노출입니다. 쿼리 스트링에 개인정보가 들어가면 흔적이 여기저기 남아요. 그리고 HTTPS를 안 쓰면 중간에서 패킷 까보는 것도 가능해지고요. 보안은 “설마” 하다가 한 번 터지면 진짜 크게 맞습니다. 이건 제가 괜히 겁주는 게 아니라, 실무에서 사고 난 케이스를 너무 많이 봤어요.
리퍼러(Referer) 헤더 문제도 은근히 자주 나옵니다. 이전 페이지 URL에 민감한 값이 들어 있었는데, 사용자가 다른 사이트로 이동하는 순간 그 URL이 통째로 전달될 수 있거든요. 나도 모르게 정보가 새는 거죠.
CSRF도 조심해야 합니다. 로그인된 사용자가 자기도 모르게 공격자가 만든 요청을 보내게 만드는 공격인데요. 예를 들어 개발자가 실수로 회원 탈퇴를 GET /user/delete?id=123 같은 형태로 만들어버렸다고 해볼게요. 공격자는 이 URL을 이미지 링크처럼 숨겨둘 수 있고, 사용자가 그 페이지를 보기만 해도 요청이 날아가 버릴 수 있습니다. 이거 한 번 상상해보면, 왜 GET을 읽기 전용으로 쓰라고 하는지 감이 확 오실 겁니다.
GET 방식의 활용 예시와 POST 방식과의 차이
GET 방식 사용 예시
GET은 웹에서 “찾고 조회하는” 기능 대부분에 붙어 있습니다. 구글 검색이 대표고요. 주변 예시로 보면 더 빨리 이해돼요.
검색 엔진 (예: 구글)
검색어가 URL 쿼리 스트링에 포함됩니다 (q=검색어).
검색 결과 URL 공유도 쉽습니다.
온라인 쇼핑몰 상품 목록
페이지 번호, 카테고리, 정렬 기준이 쿼리 스트링으로 전달됩니다.
특정 조건에 맞는 데이터를 조회할 때 GET을 씁니다 (GET /api/users/123).
구글에 “웹 개발” 검색하면 주소창이 https://www.google.com/search?q=웹+개발 이런 식으로 바뀌죠. 여기서 q=웹+개발이 서버에 전달되는 조건입니다. URL 자체가 “이 검색 결과”를 의미하니까, 복사해서 보내면 상대도 똑같이 볼 수 있고요.
쇼핑몰도 똑같습니다. ?page=2&category=electronics&sort=price_asc 이런 식으로 조건이 URL에 붙죠. 그리고 RESTful API에서는 조회는 GET이라는 약속이 거의 기본입니다. 123번 유저 정보 가져오면 GET /api/users/123 이런 식으로요. 주소만 봐도 “아, 이거 조회구나”가 읽히게 만드는 게 포인트입니다.
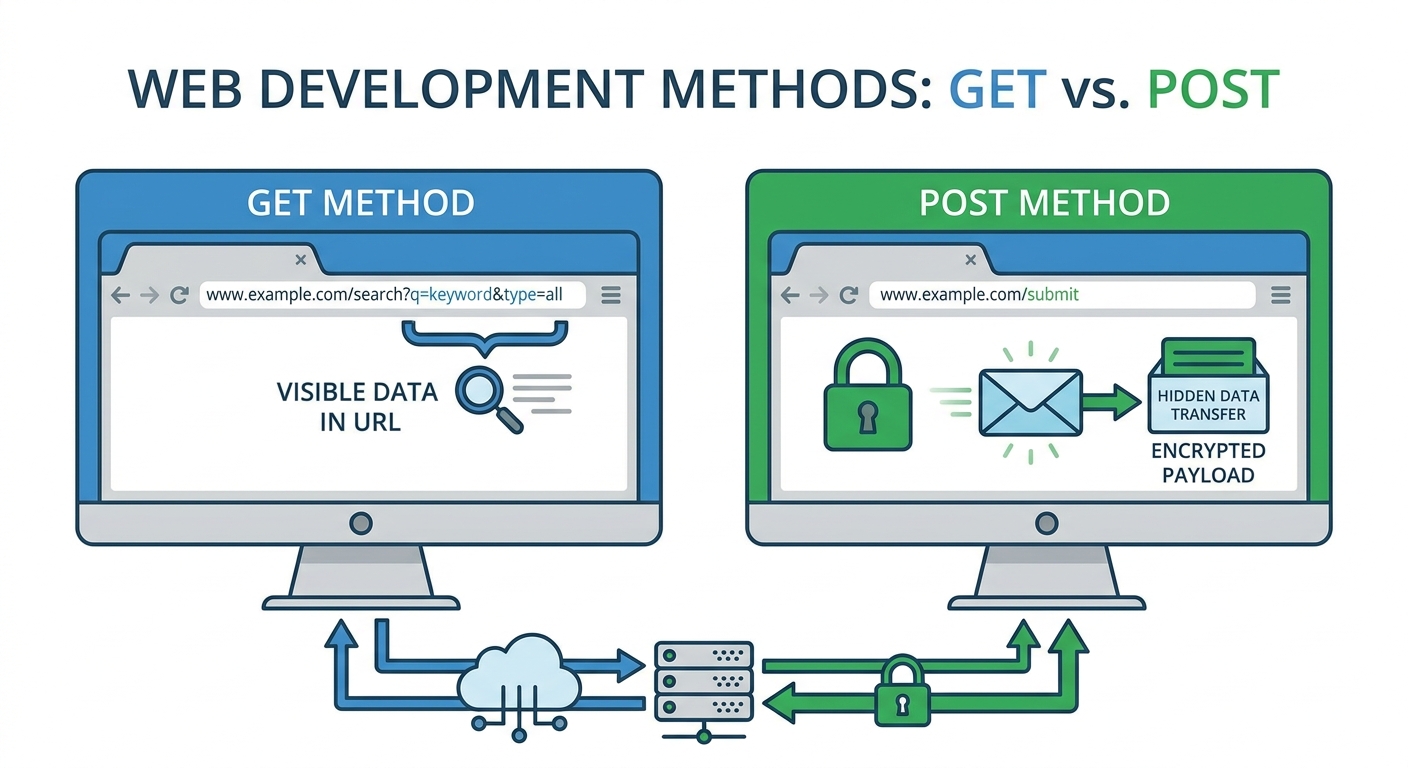
GET 방식과 POST 방식 차이
GET이랑 POST는 웹에서 제일 자주 만나는 조합인데, 역할은 확실히 갈립니다. 비유로 많이들 이렇게 말해요. GET 방식은 내용이 다 보이는 엽서, POST 방식은 봉투에 넣은 편지요.
| 구분 | GET 방식 | POST 방식 |
|---|---|---|
| 데이터 전송 위치 | URL 쿼리 스트링 | 요청 본문 (Body) |
| 가시성 | 노출됨 (엽서) | 숨겨짐 (편지 봉투) |
| 데이터 길이 | 제한적 | 무제한 |
| 캐싱 | 가능 | 불가능 |
| 멱등성 | 멱등 (여러 번 요청해도 결과 동일) | 비멱등 (요청마다 결과 달라질 수 있음) |
| 주요 사용 목적 | 데이터 조회 (읽기) | 데이터 생성, 수정 (쓰기) |
| 보안 | 취약 (민감 정보 노출) | 비교적 안전 (민감 정보 숨김) |
제일 큰 차이는 데이터를 어디에 담느냐입니다. GET은 URL에 붙여 보내고, POST는 Body에 담아서 보냅니다. 그래서 GET은 밖에서 다 보이고 길이도 제한이 걸릴 수밖에 없어요. POST는 밖에서 내용이 안 보이니까 상대적으로 안전하고, 데이터도 훨씬 많이 보낼 수 있습니다. 회원가입할 때 아이디, 비밀번호, 주소 같은 값이 POST로 가는 이유가 여기 있어요.
그리고 용도도 다릅니다. GET은 서버 데이터를 읽거나 조회할 때만 쓰는 게 원칙이고, POST는 서버 상태를 바꾸는 작업에 씁니다. 글쓰기 요청을 POST로 두 번 보내면 글이 두 개 생길 수 있잖아요. 이런 게 POST의 성격입니다. 실무에서는 이 구분을 흐리게 만들면 나중에 캐싱, 보안, 장애 대응에서 삽질이 커지더라고요.
웹은 이런 약속들로 굴러갑니다. GET은 그중에서도 제일 기본이고요. 처음엔 “그냥 주소창에 붙는 거” 정도로 보이는데, 한 번 제대로 감 잡아두면 API 설계할 때도 훨씬 편해집니다. 막히는 포인트 있으면 언제든 질문 주세요. 같이 삽질하면서 감 잡는 게 제일 빨라요.

FAQ
GET 방식과 POST 방식의 가장 큰 차이점은 무엇인가요?
데이터가 어디에 실리느냐, 그리고 용도가 뭐냐가 핵심입니다. GET은 URL에 데이터를 붙여 보내고 주로 조회에 씁니다. POST는 Body에 담아서 보내고 주로 생성/수정 같은 “쓰기” 작업에 씁니다.
로그인이나 회원가입에 GET 방식을 쓰면 왜 안 되나요?
아이디, 비밀번호 같은 값이 URL에 그대로 노출될 수 있어서요. 방문 기록, 서버 로그에 남고, 상황에 따라 유출될 가능성도 커집니다. 민감한 정보는 보통 POST로 보내는 게 안전합니다.
GET 요청이 멱등(idempotent)하다는 건 무슨 뜻인가요?
같은 요청을 한 번 하든 여러 번 하든 결과가 같다는 뜻입니다. 뉴스 기사 조회를 여러 번 한다고 기사 내용이 바뀌진 않죠. 그래서 GET은 재시도하기도 비교적 부담이 적습니다.
GET 방식으로 보낼 수 있는 데이터 길이에 정말 제한이 있나요?
표준에 “몇 글자”가 박혀 있진 않은데, 현실적으로는 제한이 있다고 보시면 됩니다. 브라우저나 서버가 너무 긴 URL을 처리 못 하게 막는 경우가 많아서요. 파일 같은 큰 데이터는 GET으로 보내기 어렵습니다.
실무에서 GET 방식은 주로 언제 사용되나요?
서버 데이터를 바꾸지 않는 조회 작업에 씁니다. 검색, 목록 조회, 상세 조회, 조건 필터링 같은 것들이요. API에서도 “리소스 조회”는 보통 GET으로 잡습니다.
안녕하세요, 코드 치는 게 일상인 12년 차 백엔드 개발자입니다. 😉
복잡해 보이는 API 공식 문서, 제가 초보자 눈높이에서 아주 쉽게 풀어드릴게요.
막히는 게 있다면 언제든 물어보세요. 같이 삽질하며 성장해 봅시다! 💪