제가 코딩 막 시작했을 때가 딱 그랬어요. “데이터를 이걸 어떻게 정리해서, 다른 시스템이랑 주고받지?” 이게 너무 막막하더라고요. 그러다 처음 제대로 마주친 게 XML(eXtensible Markup Language)이었습니다. 처음엔 꺾쇠(<, >)가 줄줄이 나와서 “이게 뭐야…” 싶었는데, 조금만 익숙해지면 그 안에 데이터에 질서를 잡아주는 규칙이 꽤 탄탄하게 들어있어요. 잘 정리된 서가처럼요. 이 글에서는 XML 파일이 뭔지부터, 실무에서 “아, 이럴 때 XML이 이렇게 쓰이는구나” 싶은 포인트들, 그리고 파일을 열어서 확인하는 방법까지 같이 훑어보겠습니다.
XML: 데이터 구조화와 효율적인 교환의 핵심
XML 파일이란?

xml 파일
XML 파일은 W3C(월드 와이드 웹 컨소시엄)에서 제정한 ‘확장 가능한 마크업 언어(eXtensible Markup Language)’ 규칙을 따르는 텍스트 파일입니다. 이름 그대로 핵심은 ‘확장성’이에요. 이 확장성이 뭐냐면, HTML처럼 정해진 태그만 쓰는 게 아니라 데이터에 맞춰 태그를 내가 직접 만들 수 있다는 뜻입니다.
예를 들어 HTML은 <p>(문단), <h1>(제목)처럼 이미 정해진 태그를 써야 하잖아요. 반면 XML은 데이터 의미에 맞춰 태그를 직접 정의할 수 있습니다. 이게 XML이 강력한 이유 중 하나예요. “이 데이터가 뭔지”를 태그로 설명해버리니까요.
그래서 XML은 ‘자기 서술적(self-describing)’ 구조를 갖는다고들 합니다. 그리고 그냥 텍스트 파일이라 보통 .xml 확장자를 쓰고, 윈도우 메모장 같은 기본 편집기로도 열 수 있어요. 사람이 읽기에도 괜찮고, 시스템이 파싱해서 처리하기도 편한 편이라서 예전부터 시스템 간 데이터 교환에 많이 쓰였습니다.
XML 태그의 주요 특징은 대충 이런 느낌입니다.
사용자 정의 태그 데이터 의미에 맞게 <책>, <제목>, <지은이> 같은 태그를 직접 만들 수 있어요.
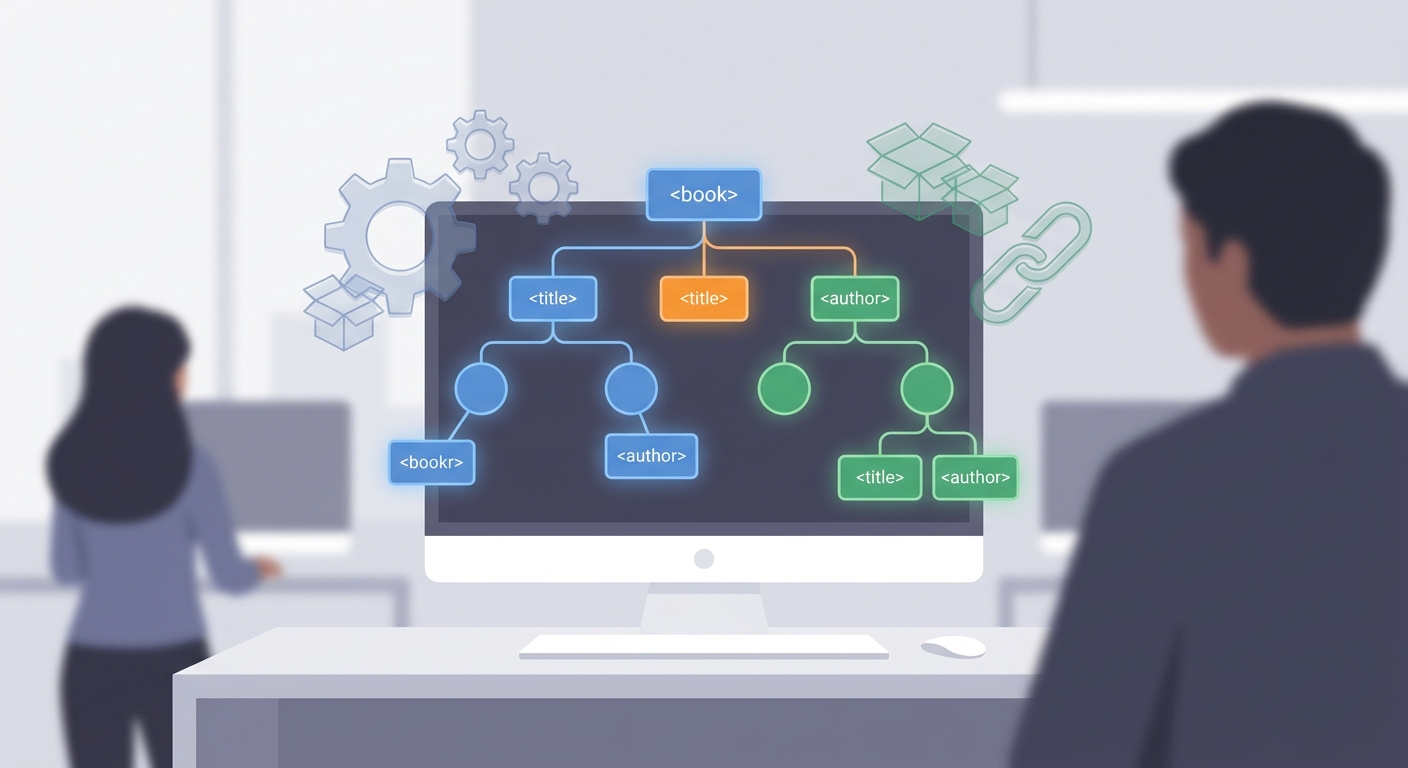
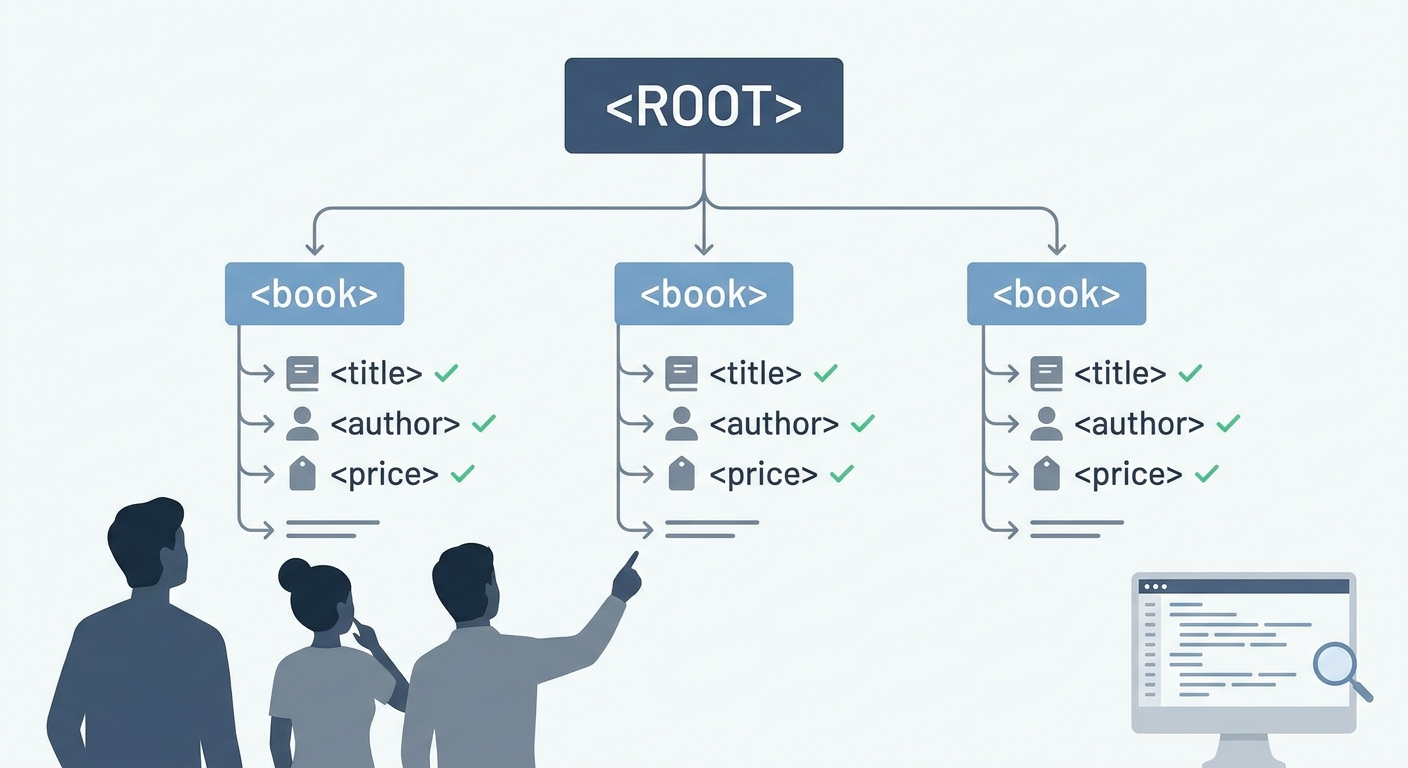
계층적 구조 최상위 요소 아래로 하위 요소가 겹겹이 들어가는 트리(tree) 구조입니다.
시작/종료 태그 쌍 모든 요소는 시작 태그와 종료 태그가 한 쌍이어야 합니다.
대소문자 구분 <Book>과 <book>은 서로 다른 태그로 봅니다.
속성(Attribute) 시작 태그 안에 이름=”값” 형태로 추가 정보를 넣을 수 있어요.
xml파일
XML 파일의 진짜 힘은 내부 구조에서 나옵니다. XML은 규칙이 꽤 엄격한 ‘계층적(hierarchical)’ 구조를 가져요. 가족 관계도처럼 루트 요소(root element)가 하나 있고, 그 아래로 자식 요소들이 들어가는 형태죠.
그리고 모든 요소는 <책>처럼 시작 태그가 있으면 </책>처럼 끝 태그가 꼭 있어야 합니다. 저도 초반에 이거 짝 안 맞춰서 에러 엄청 봤어요. 특히 대소문자까지 구분하니까 <Book>과 <book> 섞어 쓰면 바로 삽질 코스 들어갑니다.
또 요소는 ‘속성(attribute)’을 가질 수 있는데, 예를 들면 <책 종류="소설"> 이런 식으로 시작 태그 안에 이름="값" 형태로 들어갑니다. 실무에서 이 속성 때문에 변환할 때 골치 아픈 경우도 종종 있어요.
XML 문서는 보통 맨 첫 줄에 <?xml version="1.0" encoding="UTF-8"?> 같은 문서 선언으로 시작합니다. 이게 “나 XML이고, 버전은 이거고, 인코딩은 이거야”를 알려주는 거라서요. 인코딩 잘못 맞추면 한글 깨져서 멘붕 오기 딱 좋습니다.
W3C 쪽에서 XML 문서를 볼 때 자주 나오는 구분이 두 가지가 있어요.
| 상태 | 설명 | 예시 |
|---|---|---|
| Well-formed (올바른 형식) | 기본 문법 규칙(모든 태그 닫힘, 계층 구조 등)을 지킨 상태 | <root><item/></root> |
| Valid (유효한) | Well-formed 조건 충족 + DTD나 XSD 같은 ‘설계도’에 정의된 세부 규칙까지 따른 상태 | <book><title>제목</title><price>10000</price></book>(스키마에 가격은 숫자여야 함) |
유효성 검증은 “문법만 맞는지”를 넘어서 “업무 규칙까지 맞는지”를 잡아주니까, 시스템 간 교환할 때 사고를 많이 줄여줍니다.
xml file
XML은 특히 기업 간(B2B)으로 서로 다른 시스템이 데이터를 주고받을 때 진가가 나오는 편입니다. 예를 들어 SOAP(Simple Object Access Protocol) 같은 쪽이나, 일부 REST API에서도 XML을 쓰는 경우가 있어요. 한쪽은 Java, 다른 쪽은 .NET이어도, 약속된 구조로 메시지를 주고받으면 “같은 언어로 대화하는 느낌”이 나긴 하죠.
실무에서 느끼는 포인트는 이거예요. 서로 다른 기술 스택을 억지로 연결해야 할 때, 표준화된 데이터 포맷이 있으면 일이 확 줄어듭니다. 없으면… 각자 해석이 달라져서 삽질이 시작되고요.
기업 환경에서 XML이 강한 이유 중 하나가 스키마(XSD)로 무결성을 강하게 잡을 수 있다는 점입니다.
> IEEE에 발표된 한 성능 비교 연구(B. T. Le et al., 2019)에 따르면, XML은 XSD(XML Schema Definition)와 함께 사용할 때 단순 CSV보다 데이터 일관성과 정확성 면에서 더 강점이 두드러진다고 합니다.
CSV는 ‘가격’ 칸에 글자가 들어가도 막을 방법이 없잖아요. 반면 XSD를 쓰면 <가격>은 양수만, <출판일>은 날짜 형식만 이런 식으로 규칙을 박아둘 수 있습니다. 이게 쌓이면 데이터 처리 오류가 확 줄어요.

XML 파일을 어떻게 열고 확인할까요?

xml 파일 열기
XML 파일은 텍스트 기반이라 열기 자체는 쉬워요. 윈도우 메모장, macOS 텍스트 편집기로도 열립니다. 근데 초보일수록 메모장은 솔직히 비추입니다. 태그랑 값이 전부 똑같은 색으로 보이니까 구조 파악이 너무 힘들거든요.
쌩초보라면 Visual Studio Code, Sublime Text, Notepad++처럼 구문 강조(syntax highlighting) 되는 에디터를 쓰는 걸 추천드립니다. 저도 예전에 메모장으로 보다가 눈 빠지는 줄 알았어요. 이런 에디터는 태그, 속성, 값이 색으로 나뉘어서 훨씬 덜 괴롭습니다.
| 도구 유형 | 장점 | 단점 | 추천 상황 |
|---|---|---|---|
| 기본 텍스트 편집기 | 별도 설치 없이 바로 사용 가능 | 구문 강조 없음, 가독성 낮음 | 아주 간단한 파일 내용만 잠깐 확인 |
| 전문 텍스트 에디터 | 구문 강조, 코드 접기/펴기, 검색 기능 등 | 처음 설치가 필요함 | 복잡한 XML 분석 및 수정 |
| 웹 브라우저 | 트리 구조로 시각화, 설치 필요 없음 | 편집 기능 없음, 큰 파일은 느릴 수 있음 | 전체 구조를 빠르게 훑어볼 때 |
| 전문 XML 편집기 | 유효성 검증, 스키마 기반 편집, 디버깅 기능 등 | 유료인 경우가 많고 무거운 편 | 개발/검증 단계에서 정교한 XML 작업 |
그리고 생각보다 편한 방법이 웹 브라우저예요. 크롬, 파이어폭스, 엣지 같은 데로 파일을 그냥 끌어다 놓으면, 브라우저가 트리 구조로 정리해서 보여줍니다. 화살표로 접었다 펼 수 있어서, 수천 줄짜리 파일 구조 볼 때 꽤 쓸만해요.
제가 신입 때 공공기관 연구과제 정보 연동 프로젝트를 한 번 들어간 적이 있는데, 기관에서 준 XML이 구조도 복잡하고 데이터도 깨져 있고 난리였거든요. 그때 사수가 Altova XMLSpy 같은 전문 도구를 써보라고 해서 써봤는데, 진짜 신세계였습니다. 며칠 씨름하던 걸 반나절 만에 정리했던 기억이 나요. “도구가 실력이다” 이런 말이 괜히 있는 게 아니더라고요.

xml 파일 보는법
XML은 ‘열기’보다 ‘보는 법’이 더 중요합니다. 저는 XML 볼 때 나무(개별 태그)부터 보지 말고, 숲(전체 구조)부터 보라고 얘기하는 편이에요.
일단 첫 줄의 문서 선언부(<?xml ... ?>)를 보고 버전이랑 인코딩을 확인합니다. 인코딩이 틀리면 한글이 깨져서, 그 순간부터는 디버깅이 아니라 멘탈 케어가 필요해져요.
그다음은 루트 요소를 찾고, 그 아래로 구조가 어떻게 뻗는지 봅니다. 네임스페이스(namespace)가 있으면 더 주의해서 봐야 해요. 예를 들어 <title>이 책 제목일 수도 있고, 사람 직책일 수도 있잖아요. 이럴 때 xmlns:book="http://example.com/books" 같은 선언을 하고 <book:title>처럼 접두사를 붙여서 의미를 분리합니다.
XML 분석할 때 도움이 되는 팁은 이런 것들이 있어요.
- 루트 요소 확인 문서 최상위 요소부터 잡고 시작합니다.
- 계층 구조 파악 들여쓰기(indentation)로 부모-자식 관계를 눈으로 확인합니다.
- 네임스페이스 이해 선언과 사용 방식을 보고 태그 의미를 구분합니다.
- 주석 활용
<!-- 주석 내용 -->으로 의도나 섹션 설명을 파악합니다. - 쿼리 언어 사용 파일이 크면 XPath나 XQuery로 필요한 데이터만 뽑아봅니다.
파일이 너무 크면 전체를 정독하는 건 거의 불가능하죠. 이럴 때 XPath가 꽤 유용합니다. 폴더 경로 타고 들어가듯이, XML 안에서 “카테고리가 소설인 책의 제목만” 같은 걸 빠르게 찾아낼 수 있어요. 대용량 다루다 보면 이런 게 진짜 체감됩니다.

XML 데이터 처리 및 변환

xml parser
XML 파서(parser)는 XML을 “프로그램이 먹을 수 있는 형태”로 바꿔주는 도구라고 보면 됩니다. XML은 그냥 텍스트 덩어리라서, Java나 Python에서 쓰려면 파싱해서 객체 형태로 만들어야 하거든요. 그 역할을 파서 라이브러리가 해줍니다.
파싱 방식은 크게 DOM 파서와 SAX 파서로 많이 나눠요. 선택 잘못하면 바로 삽질합니다.
| 파서 종류 | 특징 | 장점 | 단점 | 추천 상황 |
|---|---|---|---|---|
| DOM 파서 | 문서 전체를 메모리에 트리 구조로 로드 | 데이터 탐색/수정이 자유롭고 조작이 편함 | 메모리 사용량이 큼, 대용량 파일에 부적합 | 파일이 작고, 수정까지 해야 하는 경우 |
| SAX 파서 | 이벤트 기반으로 순차 처리 | 메모리 사용량이 적음, 대용량 처리에 유리 | 한번 지나간 데이터는 재접근이 어려움 | 파일이 크고, 읽어서 처리만 하면 되는 경우 |
DOM은 문서 전체를 메모리에 올려서 트리로 만들어놓고, 레고판 펼쳐놓듯 여기저기 마음대로 만지는 방식입니다. 편하긴 한데 메모리를 많이 먹어요. 저도 예전에 멋모르고 1GB 넘는 XML을 DOM으로 열었다가 서버 메모리 터질 뻔해서 혼쭐난 적 있습니다.
SAX는 컨베이어 벨트처럼 처음부터 끝까지 한 번 쭉 읽으면서 이벤트를 던지는 방식이에요. 메모리를 거의 안 쓰니까 대용량에 강합니다. 대신 지나간 건 다시 보기 어렵죠. 저는 대용량 로그성 XML 분석할 때는 SAX 쪽을 더 선호하는 편이고요. 요즘은 StAX(Streaming API for XML)처럼 중간 성격도 많이 씁니다.

xml 변환
XML 변환은 XML 문서를 HTML, JSON, PDF 같은 다른 형식으로 바꾸거나, 구조만 다른 새로운 데이터 형태로 재구성하는 작업입니다. DB에서 뽑은 데이터를 보고서로 만들거나, 우리 회사 데이터를 다른 회사 시스템이 이해할 수 있게 바꿔주는 작업이 여기에 들어가요.
여기서 대표 기술이 XSLT(eXtensible Stylesheet Language Transformations)입니다. W3C 표준이고요.
XSLT는 “입력 XML에서 이 패턴을 만나면, 출력 문서에는 저렇게 만들어라” 같은 변환 규칙(템플릿)을 정의해두는 방식입니다. 처음 보면 좀 낯선데, 규칙만 잘 짜면 XML이 멋진 HTML 보고서로 바뀌는 걸 보고 꽤 신기하실 거예요. 이때 원하는 부분을 콕 집어내는 데 XPath(XML Path Language)가 같이 쓰입니다.

xml 파일 변환
실무에서는 XSLT 말고도 여러 방식으로 XML을 변환합니다. Python이면 xml.etree.ElementTree 같은 걸로 읽어서 필요한 것만 뽑아 JSON/CSV로 직접 만들기도 하고요. Java 쪽은 JAXB로 XML을 자바 객체로 매핑해서 다루는 경우도 많습니다.
XML 변환할 때는 이런 걸 미리 생각해두는 게 좋아요.
원본 데이터 형식 DTD/XSD가 있는지, 어떤 규칙을 타는지 확인합니다.
목표 데이터 형식 HTML로 갈지 JSON으로 갈지, 아니면 다른 XML로 갈지 정합니다.
변환 규칙 정의 XSLT든 코드든 매핑 규칙을 명확히 잡습니다.
데이터 무결성 변환 중 손실/오류가 없게 검증을 꼭 넣습니다.
속성 처리 XML 속성(attribute)을 목표 포맷에서 어떻게 표현할지 정합니다.
특히 XML을 JSON으로 바꿀 때 조심할 게 하나 있어요. XML에는 속성이 있는데 JSON에는 그 개념이 딱 떨어지게 없거든요. 예를 들어 <person name="John">Doe</person> 같은 걸 JSON으로 바꿀 때, name을 어디에 넣을지 팀마다/도구마다 결과가 달라질 수 있습니다. 그래서 프로젝트 들어가면 변환 규칙을 팀에서 먼저 합의해두는 게 진짜 중요해요. 이거 안 해두면 나중에 데이터 맞추느라 시간 다 날립니다.
대규모 시스템에서 XML 변환이 잘 굴러가려면, 변환 기술도 기술인데 원본 데이터 품질 관리가 같이 가야 합니다.
> 한 연구(Mahfoudh et al., 2010)에 따르면, 성공적인 데이터 교환 시스템은 변환 과정에서 원본 데이터가 목표 시스템 규칙(데이터 타입, 글자 수 제한 등)에 맞는지 검증하는 절차를 반드시 포함한다고 합니다.
이런 검증이 있어야 중간에 데이터가 누락되거나 엉뚱하게 바뀌는 걸 막을 수 있어요.
정리하면, XML은 요즘 JSON이 대세라고 해도 여전히 현업에서 많이 만나는 기반 기술입니다. 특히 스키마로 엄격하게 검증해야 하는 기업/공공 쪽에서는 아직도 XML이 강해요. 처음엔 꺾쇠 때문에 부담스럽지만, 구조만 눈에 들어오기 시작하면 생각보다 금방 친해집니다. 막히는 구간 있으면 거기서부터 같이 삽질 줄여보죠.
FAQ
Q1: XML과 HTML의 가장 큰 차이점은 무엇인가요?
A1: 목적이 다릅니다. HTML은 웹 브라우저에 “어떻게 보여줄지(표현)”가 목적이라 <p>, <h1>처럼 정해진 태그를 씁니다. XML은 데이터가 “무엇인지(의미)”를 설명하고 저장/전달하는 게 목적이라, <책>, <지은이>처럼 데이터에 맞는 태그를 직접 만들어 쓸 수 있어요.
Q2: XML의 Well-formed와 Valid는 뭐가 다른가요?
A2: Well-formed는 기본 문법을 지킨 상태입니다. 태그가 잘 닫혔고 계층 구조가 안 깨졌고 이런 것들이요. Valid는 거기서 한 단계 더 가서, DTD나 XSD 같은 설계도에 정의된 규칙(예: 가격은 숫자만)까지 만족한 상태입니다. 그래서 Valid한 XML은 Well-formed이지만, Well-formed라고 해서 다 Valid인 건 아닙니다.
Q3: DOM 파서와 SAX 파서는 언제 쓰는 게 좋나요?
A3: DOM은 문서 전체를 메모리에 올리니까 파일이 작고, 데이터를 자유롭게 수정/삭제/검색해야 할 때 좋습니다. SAX는 순서대로 한 번만 읽어서 메모리를 적게 쓰니까, 파일이 크고 읽어서 처리만 하면 될 때 유리합니다.
Q4: XSLT는 무엇이고 어디에 쓰나요?
A4: XML을 다른 형식으로 변환하는 표준 언어입니다. XML을 HTML로 바꿔서 화면에 보여주거나, 다른 시스템과 주고받기 위해 구조를 바꾸거나, JSON으로 변환하는 데도 활용됩니다. 정렬/필터링해서 보고서 만드는 용도로도 많이 씁니다.
Q5: XML 파일을 가장 간단하게 열어보는 방법은 뭔가요?
A5: 웹 브라우저로 여는 게 제일 간단합니다. 크롬이나 파이어폭스에 파일을 끌어다 놓으면 트리 구조로 정리해서 보여줘요. 편집까지 하려면 Visual Studio Code 같은 에디터를 쓰는 게 훨씬 보기 좋습니다.
안녕하세요, 코드 치는 게 일상인 12년 차 백엔드 개발자입니다. 😉
복잡해 보이는 API 공식 문서, 제가 초보자 눈높이에서 아주 쉽게 풀어드릴게요.
막히는 게 있다면 언제든 물어보세요. 같이 삽질하며 성장해 봅시다! 💪

